Compiling¶
- Python code -> Parse tree
- Parse tree -> AST
- Symbol table generated
- Code object generated
- Flow control graph generated
- Code object optimization (Peephole optimization)
- Bytecode generated
1. Lexer¶
Take the source code into each word.
- Parser/tokenizer.c -> PyTokenizer_FromString
- Parser/parsetok.c -> parsetok
- Lib/tokenize.py
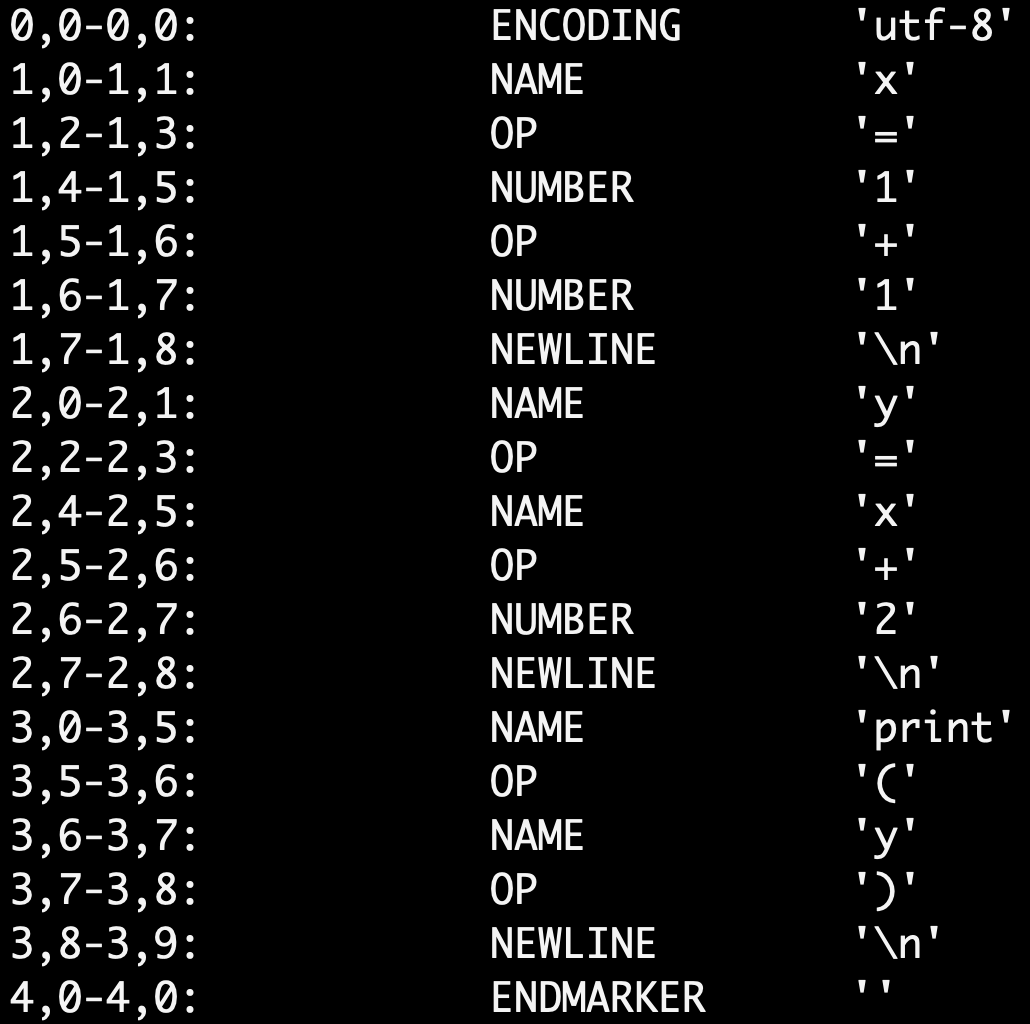
Tokenizing¶
The token is the name of some sort of symbol
For example:
a = 4
if (a <= 3):
print("hello")
so it would turn into a list like below:
- Name: a
- EQUAL: =
- NUMBER: 4
- IF: if
- LPAREN: (
- etc
python3 -m tokenize test.py
2. Parsing¶
The parser does not know what the source file means for, instead, it just knows the token generated by the lexer, and the token object would use function next() to give a token to the parser one by one.
- Python/pythonrun.c -> PyParser_ASTFromStringObject
import parser
code = "x = 2 + 2"
st = parser.suite(code)
>>> print(parser.st2list(st))
[257, [269, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'x']]]]]]]]]]]]]]]]], [22, '='], [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '2']]]]]], [14, '+'], [320, [321, [322, [323, [324, [2, '2']]]]]]]]]]]]]]]]]]], [4, '']]], [4, ''], [0, '']]
LL_parser Full Grammar specification: https://docs.python.org/3/reference/grammar.html
3. AST¶
import dis
import ast
tree = ast.parse("x=2+2")
print(type(ast.dump(tree)))
AST example:
x= 1 + 1
y= x + 2
print(y)
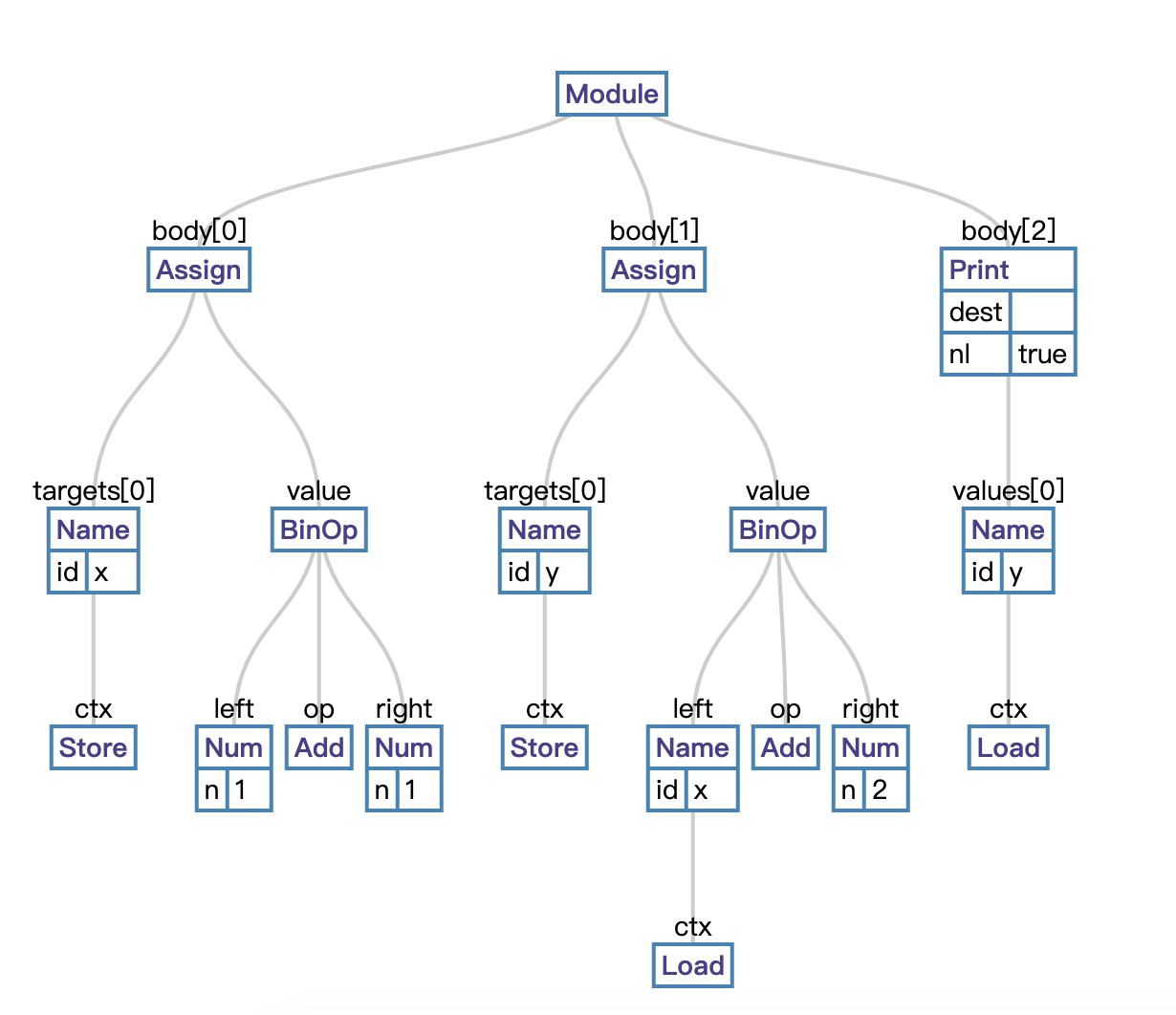
Generated by Python AST Visualizer: https://vpyast.appspot.com/
4. Compiler¶
import dis
import ast
tree = ast.parse("x=2+2")
code_obejct = compile(tree,'test.py',mode='exec')
dis.dis(code_obejct)
c = compile(open('test.py').read(), 'test.py', 'exec')